

O post de hoje é uma representação integral de um dos capítulos da tese de Doutorado de Cesar Diniz, um dos sócios fundadores da empresa. A reprodução do material aqui exposto é portanto livre e encorajada, desde que respeitados os devidos mecanismos de citações acadêmicas. Interessou-se pelo texto, basta cita-lo e aqui uma forma de faze-lo:
C. Diniz, “Três Décadas de Mudanças na Planície Costeira Brasileira: O Status Dos Manguezais, da Aquicultura e Salicultura a Partir de Séries Temporais Landsat e Técnicas de Aprendizado de Máquina”, Tese de Doutorado, Universidade Federal do Pará – UFPA, 2021.
Neste post vamos tratar, de maneira um pouco mais detalhada, sobre a Avaliação da Acurácia de um mapa, e ao final, apresentar a maneira de calcular as mais conhecidas métricas de acurácia, todas extraídas de uma matriz de confusão. Chega de por menores e vamos ao post…
A ANÁLISE DE ACURÁCIA
O princípio fundamental da análise de acurácia de um dado temático, passa pela comparação cruzada entre a classificação produzida (dado a ser avaliado), contraposta a uma referência espacial (considerada como verdade). Sendo a referência e o dado a ser avaliado, necessariamente representantes do mesmo espaço, do mesmo período de tempo e do mesmo universo categórico (classe ou tema). Para que então, através da distribuição de pontos amostrais, sorteados seguindo o rigor estatístico de designs amostrais, se consiga comparar categoricamente os dois dados, a classificação produzida e o dado de referência (Foody 2002, 2009, Olofsson et al. 2014, Stehman 2014)
Portanto, para existir análise de acurácia, há de existir dado de referência. Em geral, estes dados podem ser obtidos por meio pontos coletados em solo (verdade de campo), imagens de satélite ou fotografia aérea. A escolha por dados satelitários, se tornou cada vez mais comum, em razão do baixo custo de aquisição de imagens orbitais frente ao custo de deslocamento em campo ou do aluguel de aeronaves (Finegold et al. 2016, Olofsson et al. 2014).
Neste ponto, os dados orbitais ou fotográficos devem privilegiar, quando possível, o uso de imagens com resolução espacial mais alta que o dado de suporte a classificação. Deve-se ponderar, porém, a história da fotografia aérea e das imagens orbitais, não sendo incomum a inexistência de dados de alta resolução para séries temporais pretéritas e muito longas. Neste caso, assume-se que a análise comparativa deve ser feita sobre a mesma imagem submetida ao processo de classificação.
Por se tratar essencialmente de uma comparação matricial, a tabulação cruzada ou tabela/matriz de contingência, se tornou a forma mais comum de alcançar a análise de acurácia entre dados espaciais. Vale ressaltar, que a tabulação cruzada é ferramenta genérica de análise de dados, e, portanto, seu uso pode estar atrelado a diferentes objetivos analíticos (Finegold et al. 2016, Foody 2002, 2009, Olofsson et al. 2014, Stehman 2014). Neste sentido, quando usada para calcular a proporção de erros ou acertos entre dois conjuntos de dados, leva o nome de “Matriz de Confusão” ou “Matriz de Erro”. Porém, quando se está avaliando a transição entre classes temáticas ao longo do tempo, ganha o nome de “Matriz de Transição”.
Como qualquer matriz, a de Confusão ou Erro, é disposta em linhas e colunas. As linhas em geral, correspondem a distribuição, classe a classe, dos dados inerentes a classificação, ao passo que as colunas, dispõem os dados de referência. Aqui, vale ressaltar, que a posição ocupada por referência e classificação, seja em linhas ou colunas, é absolutamente arbitraria e, portanto, dependente da vontade e gosto do usuário. No mundo da computação, é comum a disposição de referências em linhas. Por outro lado, para o mundo do sensoriamento remoto, é mais comum que as referências sejam dispostas nas colunas (Figura 1).

Figura 1 – Disposição básica de uma Matriz de Confusão/Erro. Em A, nas linhas (rótulo em azul) estão dispostas as classificações e nas colunas (rótulo em amarelo) os dados de referência. Para cada classe, em linhas ou colunas, há um somatório contabilizado, ∑A,∑B,∑C. O termo ∑T, refere-se a soma agregada do total de todas as classes. A diagonal principal, em verde, representa os valores. verdadeiros, concordantes, entre cada classe; VA, VB, VC. Em magenta, a cima da diagonal, os falsos positivos (FP). Em laranja/pastel, a baixo da diagonal, os falsos negativos (FN). Em B, denota-se que a inversão do posicionamento das referências e classificações, em linhas ou colunas, inverte a posição de FN e FP, bem como de todas as métricas de acurácia a eles relacionadas.
A posição ocupada por determinado elemento em uma Matriz de Confusão, é sempre dependente de como estejam organizados os rótulos de referência e de classificação, e carregam consigo o significado estatístico do elemento. Uma matriz de erro, tem essencialmente 3 posições principais: Os valores verdadeiros para cada classe (VA, VB, VC, etc.), sempre posicionados na diagonal principal da matriz. Os falsos positivos (FP), na organização vista na Figura 1A, posicionados acima da diagonal principal. E, por fim, os falsos negativos (FN), localizados sob a diagonal principal. A inversão do posicionamento das referências e classificações, em linhas ou colunas, inverte a posição de FN e FP (Figura 1B), bem como de todas as métricas de acurácia a elas relacionadas.
É absolutamente fundamental que compreendamos os conceitos práticos por trás dos elementos de uma matriz de erro. Assim, temos que o termo FP, refere-se a discordâncias de comissão, ou seja, por adição indevida do rótulo “A” a uma resposta referenciada como “não-A”. Por esta razão, são chamados de “Falsos-Positivos”. Por outro lado, os erros de falsos-negativos (FN), denotam omissão do classificador, portanto, uma classe classificada como “não-A”, é referenciada como pertencente a “A”. Por fim, as respostas verdadeiras/concordantes são agrupadas na diagonal principal, constituindo acertos ou concordância entre referência e classificação.
Uma vez construída a estrutura fundamental de uma matriz de erros, podemos então extrair as métricas de acurácia, Figura 2A e B. Classicamente, as métricas são relações estatísticas envolvendo as proporções entre erros e acertos, tanto globais, envolvendo a matriz como um todo, quanto os individuais, pertencentes a cada uma das categorias. As métricas mais comumente utilizadas na análise de dados espaciais são:
- Acurácia Global (AG):
- Erro Global (EG):
- Acurácia do Consumidor (AC):
- Acurácia do Produtor (AP):
- Erros de Omissão (EO):
- Erros de Comissão (EC):
- Erro de Quantidade (QD):
- Erro de Alocação (AD):
A acurácia global (AG), é uma medida percentual da quantidade de amostras corretamente classificadas, em relação ao total de amostras disponíveis. O Erro Global (EG) por usa vez, é sua medida complementar e informa erro percentual global da matriz. A formulação de ambos é dada por:
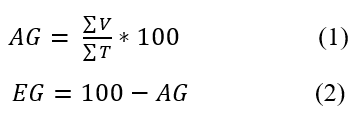
Onde,
V, representa os valores corretamente classificados,
T, representa o total de amostras disponíveis, e
AG, acurácia global.
A acurácia do consumidor (AC), ou do usuário, é a medida de acurácia do ponto de vista do usuário/consumidor do mapa. Aqui, a acurácia basicamente diz ao usuário com que frequência a classe do mapa estará realmente presente no solo ou em sua referência. É também conhecida como medida de confiabilidade (reliability). O erro de comissão (EC) é complemento de AC e nos informa a quantidade de classificações associadas a falsos positivos ou falsos alarmes. A formulação de ambas é dada por:

Onde,
V, representa os valores corretamente classificados,
n, representa a classe a ser calculada. Devendo n, ser substituído por cada classe da matriz,
c, é o índice que representa a distribuição dos dados de classificação
EC, refere-se ao Erro de Comissão e
AC, para Acurácia do Consumidor.
A acurácia do produtor (AP) é a acurácia do ponto de vista do criador/produtor do mapa. Esta é a frequência com que as características reais no solo são mostradas corretamente no mapa classificado ou a probabilidade de uma determinada cobertura/uso da terra ser classificada como tal no mapa. A AP é complementada pelo erro de omissão (EO), que nos informa a quantidade percentual de erros de omissões, ou seja, classes que deveriam ter sido detectadas, mas que por alguma razão foram omitidas da classificação. A formulação de AP e EO são dadas por:
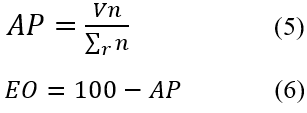
Onde,
V, representa os valores corretamente classificados
n, representa a classe a ser calculada. Devendo n, ser substituído por cada classe da matriz,
r, é o índice que representa a distribuição dos dados de referência,
EO, refere-se ao Erro de Omissão e
AP, para Acurácia do Produtor.
Mais recentemente as métricas de Erros de Quantidade (Quantity Disagreement – QD) e Erros de Alocação (Allocation Disagreement – AD) se tornaram mais populares. Ambas as métricas fornecem mais pistas para a identificação de eventuais falhas de uma classificação digital, separando a natureza dos discordâncias identificadas em erros de quantidade e erros de alocação, característica ausente em seu predecessor, o coeficiente de Kappa (Pontius & Millones 2011, Pontius & Santacruz 2014). A formulação de QD e AD são dadas por:

Onde,
Q, representa a diferença das quantidades totais de amostras classificadas e referenciadas.
x, é o índice que representa a classe/rótulo de cada categoria existente.
c, é o índice que representa a distribuição dos dados classificados.
r, é o índice que representa a distribuição dos dados de referência,
T, representa a o total de amostras disponíveis,
QD, refere-se aos erros de quantidade,
AD, refere-se aos erros de alocação e
EG, para Erro Global.
De modo geral, se as discordâncias de quantidade (QD) forem relativamente altas, haverá então diferenças substanciais nas quantidades totais de amostras categorizadas pela referência ou pela classificação. Por outro lado, se a discordância de alocação for alta, há de existir diferenças substanciais na alocação espacial das categorias. Por exemplo, na classificação da classe urbano, sobre um local onde a superfície é florestal. Classicamente, erros de quantidade e alocação que superarem a margem de erro de 0.1 (10%), já são considerados relativamente altos
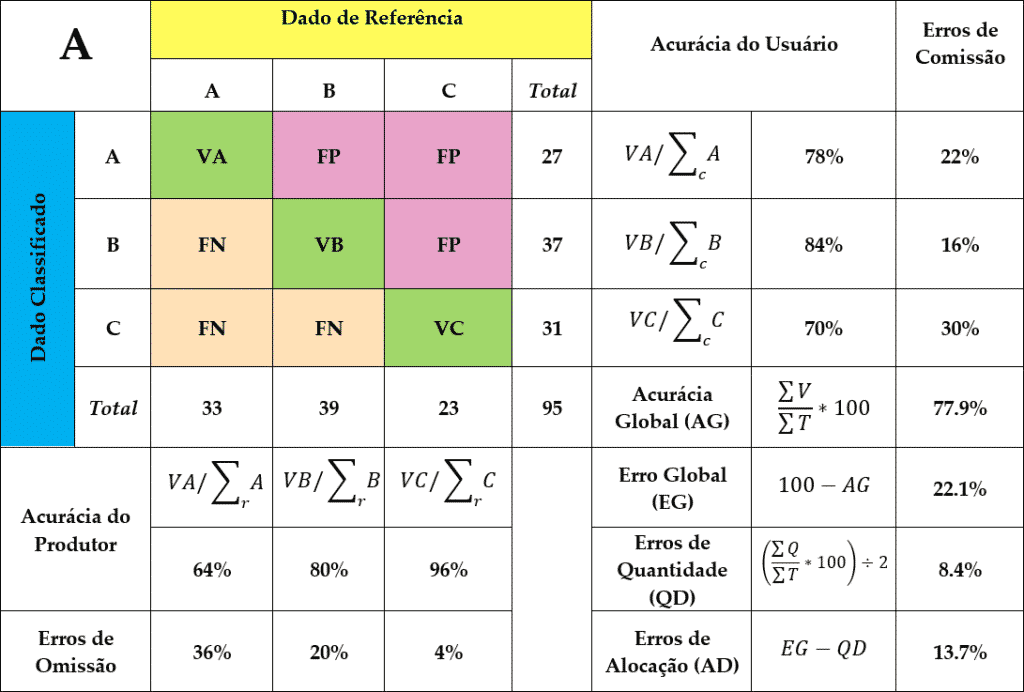

Figura 2 – Métricas de Acurácia. Classicamente, as métricas são relações estatísticas envolvendo as proporções entre erros e acertos, tanto os globais, envolvendo a matriz como um todo, quanto os individuais, de cada uma das categorias. As métricas mais comumente utilizadas na análise de dados espaciais são; Acurácia do Consumidor (ou do Usuário) – AC, Acurácia do Produtor – AP, Erros de Omissão – EO, Erros de Comissão – EC, Acurácia Global – AG, Erros de Quantidade – QD e Erros de Alocação – AD. Em A, matriz com o rótulo das posições. Em B, matriz com quantidades absolutas de cada classe.
Mas atenção, para o cálculo de QD deve-se inicialmente calcular o módulo da diferença de amostras totais para cada uma das classes (|Qx,c – Qx,r|). Assim temos o exposto na Figura 3
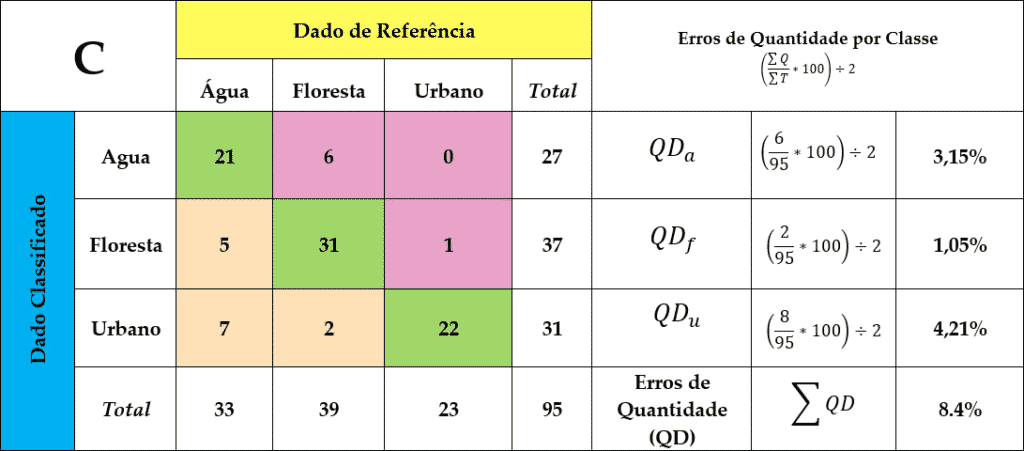
Figura 3 – Cálculo do Erro de Quantidade (QD) agregado e por classe. Para o cálculo de QD deve-se inicialmente calcular o módulo da diferença de amostras totais para cada uma das classes (|Qx,c – Qx,r|) e então agregar-se o resultado para alcançar o Erro de Quatidade da matriz [∑QD]. Assim temos, QDa , QDf e QDu como |33-27|, |39-37| e |23-31|. Perfazendo um erro por classe de 3,15%, 1,05%, 4,21%, que agregados resultam no erro de quantidade de 8.4%.
REFERÊNCIAS
Finegold, Y et al. 2016. “Map Accuracy Assessment and Area Estimation: A Practical Guide.” Rome: Food and Agriculture Organization of the United Nations.
Foody, Giles M. 2002. “Status of Land Cover Classification Accuracy Assessment.” Remote Sensing of Environment 80(1): 185–201.
Foody, Giles M. 2009. “Classification Accuracy Comparison: Hypothesis Tests and the Use of Confidence Intervals in Evaluations of Difference, Equivalence and Non-Inferiority.” Remote Sensing of Environment 113(8): 1658–63. http://www.sciencedirect.com/science/article/pii/S0034425709000923.
Olofsson, Pontus et al. 2014. “Good Practices for Estimating Area and Assessing Accuracy of Land Change.” Remote Sensing of Environment 148: 42–57. http://dx.doi.org/10.1016/j.rse.2014.02.015.
Pontius, Robert Gilmore, and Marco Millones. 2011. “Death to Kappa: Birth of Quantity Disagreement and Allocation Disagreement for Accuracy Assessment.” International Journal of Remote Sensing 32(15): 4407–29. http://dx.doi.org/10.1080/01431161.2011.552923.
Pontius, Robert Gilmore, and Alí Santacruz. 2014. “Quantity, Exchange, and Shift Components of Difference in a Square Contingency Table.” International Journal of Remote Sensing 35(21): 7543–54. http://dx.doi.org/10.1080/2150704X.2014.969814.
Stehman, Stephen V. 2014. “Estimating Area and Map Accuracy for Stratified Random Sampling When the Strata Are Different from the Map Classes.” International Journal of Remote Sensing 35(13): 4923–39. https://doi.org/10.1080/01431161.2014.930207.



This deep dive into accuracy metrics is fascinating. The concept of comparing a classification against a ‘ground truth’ is universal-it applies equally to environmental modeling and validating complex digital transactions. Maintaining data integrity, whether analyzing mangroves or ensuring a smooth user experience on a platform like fb001 slot, requires rigorous, multi-layered validation. Excellent academic sharing!
ozempic cost
ozempic cost
finasteride 1mg women
finasteride 1mg women
wish you all the best
avanafil price australia
avanafil price australia
无话可说,只是看看
This deep dive into accuracy metrics is crucial. The principle of comparing a derived model against a ‘ground truth’ reference is universal-whether analyzing mangroves or ensuring data integrity in a secure platform. High accuracy is paramount in any complex system, much like validating diverse lucky game apk games. Excellent, foundational material!
A888bet? Yeah, I mess with that. Plenty of options, you know? Worth checking out: a888bet
Heard some good things about 797bet. Giving it a shot now. See for yourself: 797bet
Alright folks, 69bet win has been good to me. Gotta say, worth a look. Hit it up: 69bet win
cenforce 100mg for sale
cenforce 100mg for sale
https://shorturl.fm/4iI8H
Gave 7777winbet a shot recently. Interface is slick, and the game selection is pretty broad. Had a smooth experience overall. I think it’s worth a try for sure if you are hunting for a different place to play. Take a peek: 7777winbet
bggbetbonus is alright. Registration was quick and simple. Lots of bonus options available. Could be your new favorite gambling spot. Give them a look: bggbetbonus
Downloaded the 29betloginapp the other day. Super convenient to play on the go! Interface is clean and it’s quick to load. Thumbs up from me. 29betloginapp
I appreciate the rigorous approach to accuracy metrics. The concept of validating a model against a ‘ground truth’ is universal-it’s key in everything from environmental mapping to ensuring platform security and financial integrity, which is vital when managing accounts on sites like GTaya online casino. Excellent foundational material!
sildenafil citrate pictures
sildenafil citrate pictures
bd1777det showed up when I was searching around. Gotta say, not the flashiest site, but it runs smooth and the games are what they are. Check it out bd1777det if you’re looking for something different
fe777login is smooth. Quick to log in, and the games are solid. No complaints so far. Give it a shot if you’re looking for something new. Check it out fe777login
Mxrich88 is alright! Easy to navigate and I won a bit there too. Keep it 100, worth trying. Have fun and visit them here: mxrich88
色即是空,空即是色
wish you best and best
Mass comment blasting: $10 for 100k comments. All from unique blog domains, zero duplicates. I will provide a full report and guarantee Ahrefs picks them up. Email mailto:helloboy1979@gmail.com for payment info.If you received this, you know Ive got the skills.
wish you all the best
zoloft medication cost
zoloft medication cost
lasix diuretic
lasix diuretic
amoxicillin clavulanic acid
amoxicillin clavulanic acid
diflucan over the counter south africa
diflucan over the counter south africa
doxycycline hyclate 100mg for dogs
doxycycline hyclate 100mg for dogs
prevacid 15 mg
prevacid 15 mg
jalyn
jalyn
linezolid antibiotic
linezolid antibiotic
mirtazapine 15 mg tablet price
mirtazapine 15 mg tablet price
Yo! Just jumped over to mbet1. Quick registration process and decent odds. I’ve seen worse. Give it a try, you might just end up winning! Check it out yourself mbet1!
Hey! Giving l666bet a shot today. I’m liking the vibe so far, the platform is user-friendly and easy to get around. Worth a go if you’re looking for some online action. Find fun stuff right here l666bet!
Alright, friends! Just tried my luck at kjcrr88 and gotta say, not bad! The site’s pretty smooth and the games selection keeps things interesting. Definitely worth checking out for a bit of fun. Go have a look kjcrr88!
sildenafil precio
sildenafil precio
Excellent insights on accuracy assessment! Your approach to validating classifications through confusion matrices aligns perfectly with how we evaluate AI agent interactions in the openclaw community. The rigorous statistical sampling methods you describe are equally crucial for training reliable machine learning models.
Heard some buzz about s66 plus. Gave it a shot, and I’m not disappointed. Simple interface and fun games. Check it out now: s66 plus
Just tried Bet 169. Not bad at all. The site is user-friendly, and I like the variety of betting options. Check it out if you’re looking for something new. Definitely worth a punt! Find it at bet 169.
Yo, fam! Heard tải b29.bet was the real deal. Got it right here, easy peasy. Gotta see if I can win big now! tải b29.bet
看不懂但大受震撼
Weathernoho has become my daily go-to for checking the weather. Accurate forecasts and a sweet design. Can’t ask for more. Get your weather fix here: weathernoho
66biolink, I saw it trending and decided to take a look. It’s really useful for my social media. Clean interface, easy to use, and does what it says. Check it here: 66biolink
123winonline exists, honestly I have not tried. I think you should! Give a try on my behalf: 123winonline.
CashTornadoApp, this app is a whirlwind of games! I was surprised by graphic quality and available options. It is definitely something you should check out! Get spinning cashtornadoapp!
Kèo bóng đá Bet88, for the football fans! If you’re looking to get in on some predictions and odds, this site seems like a decent place to start. Do your research, though! Get your bets in kèo bóng đá bet88!
Pixbetcassino…another option is available in Brazil. Can you play with Pix? If so, that’s pretty cool and convenient, and I would like to know if I could win here at pixbetcassino
77ph has a fun selection and ease of access that have made returning a regular part of the rotation. Give them a look if you’re interested. Click here for the goodies 77ph
399BetApp just made things easier for me, placing bets is easier than ever. Get on the action with this app. Super easy and smooth. Download the app and get betting! 399betapp